
Automated Hate Speech and Offensive Language Detection
Automated Hate Speech and Offensive Language Detection
Summary
• Developed a bag of words model to detect and classify hate speech and offensive speech on Twitter to help monitor and filter out extreme tweets more efficiently based on the model.
• Applied our classification model to real world data by drawing thousands of tweets through Twitter API. Successfully filtered out over 95% of the benign class and retrieve over 60% of the tweets that contain hate language.
Objective and Data
It is an increasingly important problem that hate speech appear more and more often in tweets. We try to build a classifier to help administration to monitor and filter out tweets with extreme language more efficiently. We train the classifier based on the labeled data on the Github. The data contains 24000 tweets, each labeled by 6 humans. The label is either “the tweet contain hate language” or “the tweet don’t contain hate language but contain offensive language” or “the tweet contain neither”.
“Data” 
Data Preparation
In the data preparation part, we
• Remove URLs and emoij using regular expressions
• Tokenize text based on space characters and convert words into lowercase
• Remove words beginning with Mention (@)
• Convert contractions to formal writing based on a dictionary we build, and then remove punctuations
• Remove words with length less than 2 and words that are not alphabetic
• Remove stop words. For the stop word list, add some common words in tweets, like ’rt’ and ’ff’, and remove negation words which may be important in bigram features.
• Stem and lemmatize words to convert inflectional forms and derivational forms of words to base forms.
In terms of extracting features, we can choose n-gram, like unigram and bigram, and different modes including TFIDF, count and binary. Besides, we can use parts of speech of each word in the same way. We also take advantage of some other features. First, there are some statistics of text including the number of words, characters, syllabus, URLs, hashtags and mentions; second, Flesch-Kincaid grade level and Flesch readability ease both are used to measure readability of text; third, sentiment analysis indicators based on VADER are used to evaluate how positive or negative a piece of text is.
Models
In the model trainning part, We have tried Logistic Regression, support vector machine, random forest. I am responsible for tuning the SVM model. Due to the high dimension of the data, kernelized SVM model is a good fit for this problem. It is worth noting that tuning class weight is crucial in building SVM in this case. The data was unbalanced, that is to say, the number of tweets with offensive language outweighed the other two categories, especially twitters with hate language. When the class weight was set to be default(none), SVM tended to classify almost all the tweets to the offensive language categories as it minimize the loss function, which was the last thing we want.
Setting the class weight to be balanced increased the price to mis-classify twitters with hate language, and increased the percentage of true positive for it.
We implemented grid search to optimize the hyper-parameter like kernel(rbf or sigmoid or linear or poly), regulation type(L1 or L2), C, and class weight(balanced or none). And we used iteration to select the features that could optimize the model performance from the features set(n-grams: 1 gram, 2 gram, modes: binary, count, frequency, tfidf) We tested each model using 5-fold cross-validation, holding out 10% of the samples for evaluation to prevent over-fitting. After using grid search to iterating hyper-parameters and different sets of features, we found that the model with linear kernel, L2 regulation, C=1, balanced class weight and uni-gram and binary features performed better than the models with other combinations of hyper-parameters and features.
Results
excerpt: “Results” 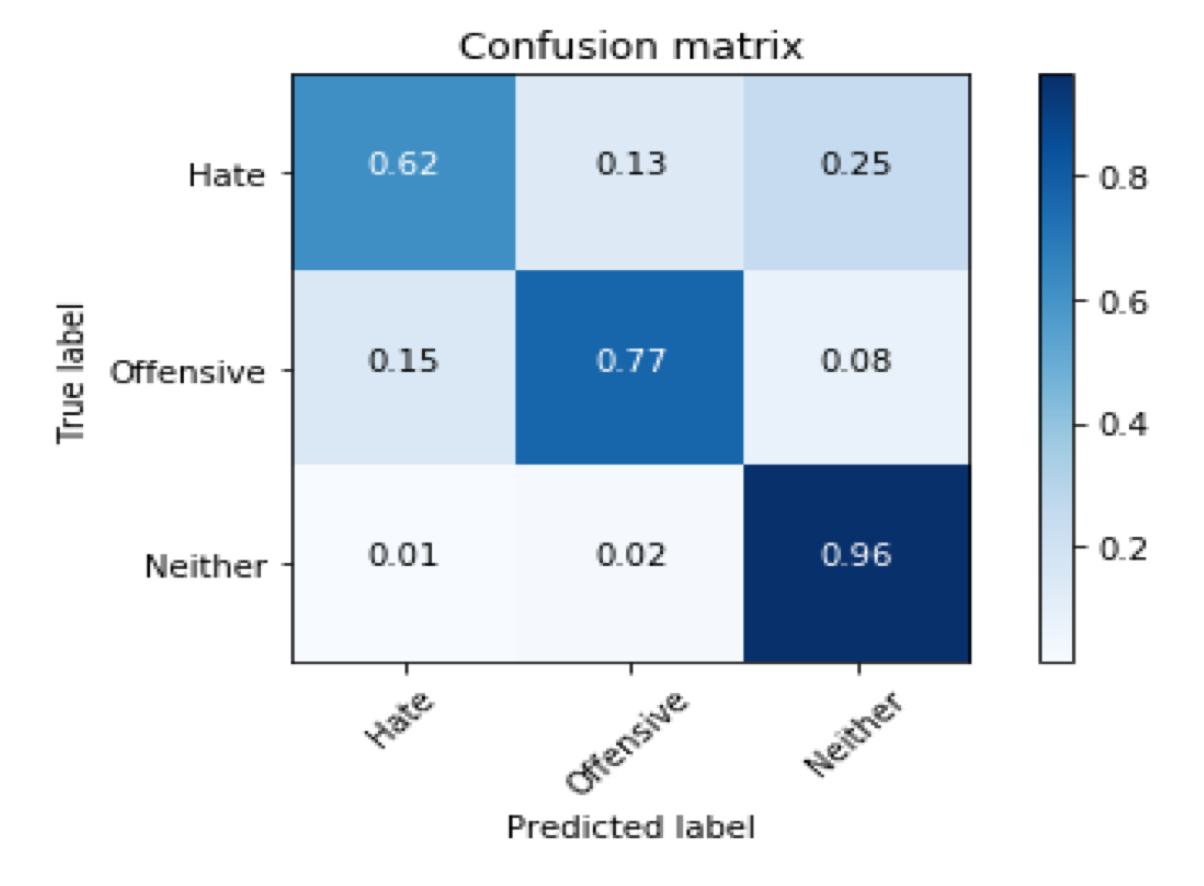
we applied our classification model to real world data by drawing thousands of tweets through Twitter API. We successfully filtered out over 95% of the benign class and retrieve over 60% of the tweets that contain hate language.